
強化学習×推薦アルゴリズムを試せる環境「RecoGym」入門
今回は前回に引き続きRecoGymについて書いていきたいと思います.
前回はRecoGymを試すための環境構築の部分のみだったので今回は実際にコードを見ていきたいと思います.RecoGymのGetting Startedをベースに話を進めていきます.
RecoGymとは?
前回の記事を参照してください.
強化学習×推薦アルゴリズムを試せる環境「RecoGym」とは?
環境のやりとりの記述
強化学習エージェントを学習させようと思うと学習エージェントがやりとりを行う環境を準備しなければなりません.その環境をOpenAIGymが用意してくれています.そしてそのOpenAIgymをベースにRecoGymは作られています.そのため,私たちはその環境と学習エージェントがやりとりする手続きと学習エージェントの学習部分をプログラミングすればいいということになります.
まずは,Gymから環境を引っ張って来ます.
import gym, reco_gym
# env_0_args is a dictionary of default parameters (i.e. number of products)
from reco_gym import env_1_args, Configuration
# You can overwrite environment arguments here:
env_1_args['random_seed'] = 42
# Initialize the gym for the first time by calling .make() and .init_gym()
env = gym.make('reco-gym-v1')
env.init_gym(env_1_args)
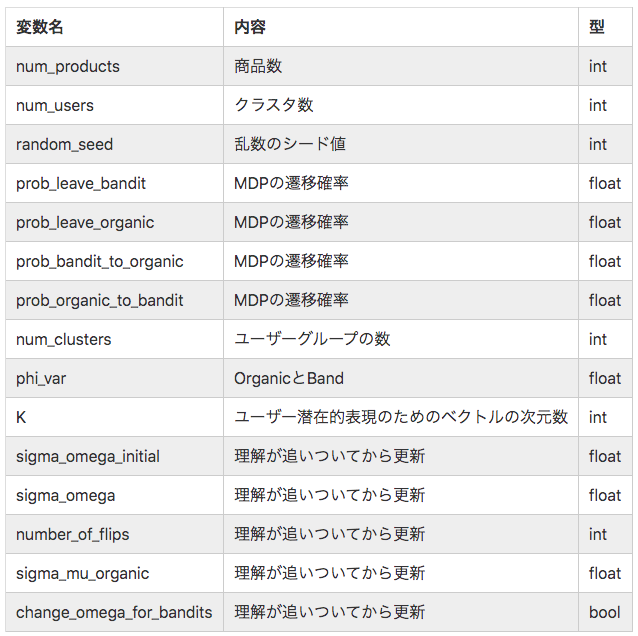
ここで,env_1_argsは環境に関する情報を保持する辞書型となります. Configurationは環境の設定を保持するクラスになります.あとで出て来ますが,エージェントに持たせたりします.env_1_argsの設定情報をいかにまとめます(わかる範囲で).ここではrandom_seedを42に設定しています.
RecoGymではOffline学習環境とOnline学習環境が用意されているので,それぞれ見ていきたいと思います.
Offlineの場合
まずOfflineでの処理の流れに関して見ていきます.Offlineでは環境内で設定された固定方策に従って推薦を行い,何を推薦したか,その結果得られた観測,報酬,終了したかどうかといった情報が環境から返されます.
# .reset() env before each episode (one episode per user).
env.reset()
done = False
# Counting how many steps.
i = 0
observation, reward, done = None, 0, False
while not done:
action, observation, reward, done, info = env.step_offline(observation, reward, done)
print(f"Step: {i} - Action: {action} - Observation: {observation.sessions()} - Reward: {reward}")
i += 1
まず,環境をリセット env.reset() します.ここでの返り値はNoneになります.これが観測observationの初期値になります.次に報酬rewardとタスクが終了したかどうかを表すdoneをそれぞれ0とFalseに初期化します.次にOfflineのコマンドとして特徴的なのがstep_offlineです.ここにobservationとreward,doneを渡すと行動(固定方策が選択した推薦)action,観測observation,報酬reward,終了するかどうかdone,infoが返されます.これをwhile文で繰り返します.
環境から返される状態と選択された行動
step_offline を実行した際に返ってきた値が下記になります.
略
Step: 62 - Action: {'t': 71, 'u': 0, 'a': 9, 'ps': 0.1, 'ps-a': array([0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1])} - Observation: [] - Reward: 0
Step: 63 - Action: {'t': 72, 'u': 0, 'a': 5, 'ps': 0.1, 'ps-a': array([0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1])} - Observation: [{'t': 73, 'u': 0, 'z': 'pageview', 'v': 5}, {'t': 74, 'u': 0, 'z': 'pageview', 'v': 2}, {'t': 75, 'u': 0, 'z': 'pageview', 'v': 2}] - Reward: 0
Step: 64 - Action: {'t': 76, 'u': 0, 'a': 3, 'ps': 0.1, 'ps-a': array([0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1])} - Observation: [] - Reward: 0
Step: 65 - Action: {'t': 77, 'u': 0, 'a': 5, 'ps': 0.1, 'ps-a': array([0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1])} - Observation: [{'t': 78, 'u': 0, 'z': 'pageview', 'v': 2}] - Reward: 0
まず 行動Actionの項目について記述します.Step 62で返ってきた値を説明していきます.
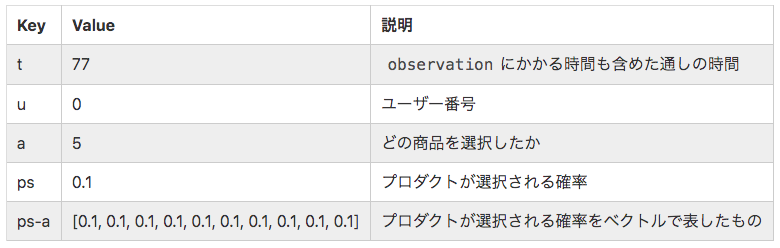
時間に関してですが,エージェントが推薦するのに1費やし,ユーザーがその推薦に対して何かしらのアクション(pageviewなど)をするのに1費やすというような設定になっているようです.この例の場合だと,時間71にユーザー0に対して商品9を推薦したということを意味しています.psはプロダクトを選択する確率を表しています.Offlineでは環境内部にある固定方策で行動を決定すると書きましたが,どうやらランダムで決定しているようですね.そのランダムの偏りをここで指定できるようです.
次に観測observationについて見ていきます.観測はStep 65の場合を取り上げます.

これは,時間78でユーザー0がプロダクト2をクリックしたということを表しています.プロダクト5を推薦して,ユーザーはプロダクト2をクリックしているので,ダメですね.外してしまっています.そのため,Rewardは0で返ってきているというような結果です.
Onlineの場合
次にOnlineの場合について見ていきます.Onlineでは学習をしながら推薦をするというような状況が考えられています.推薦を行って,その推薦に対する観測が返ってくるというような流れを繰り返しています.
# Create list of hard coded actions.
actions = [None] + [1, 2, 3, 4, 5]
# Reset env and set done to False.
env.reset()
done = False
# Counting how many steps.
i = 0
while not done and i < len(actions):
action = actions[i]
observation, reward, done, info = env.step(action)
print(f"Step: {i} - Action: {action} - Observation: {observation.sessions()} - Reward: {reward}")
i += 1
まず始めに,行動空間(学習エージェントが取ることのできる行動の集合)を定義します.その後はOfflineの場合と同じようにenv.reset()で環境を初期化します.その後,学習のループに入ります.学習ループでは,Open AI gymと同じような流れになります.行動actionを選択して,環境にstep関数に行動を渡すことで環境とのインタラクションをおこないます.環境は観測,報酬,タスクが終了するかどうかの真偽値を返します.
環境から返される状態と選択する行動
実行の結果の抜粋を以下に示します.
Step: 4 - Action: 4 - Observation: [] - Reward: 0
Step: 5 - Action: 5 - Observation: [{'t': 6, 'u': 0, 'z': 'pageview', 'v': 4},
{'t': 7, 'u': 0, 'z': 'pageview', 'v': 4}, {'t': 8, 'u': 0, 'z': 'pageview', 'v': 4}, {'t': 9, 'u': 0, 'z': 'pageview', 'v': 4}, {'t': 10, 'u': 0, 'z': 'pageview', 'v': 4}, {'t': 11, 'u': 0, 'z': 'pageview', 'v': 6}, {'t': 12, 'u': 0, 'z': 'pageview', 'v': 4}, {'t': 13, 'u': 0, 'z': 'pageview', 'v': 4}, {'t': 14, 'u': 0, 'z': 'pageview', 'v': 4}, {'t': 15, 'u': 0, 'z': 'pageview', 'v': 6}, {'t': 16, 'u': 0, 'z': 'pageview', 'v': 4}, {'t': 17, 'u': 0, 'z': 'pageview', 'v': 1}, {'t': 18, 'u': 0, 'z': 'pageview', 'v': 4}, {'t': 19, 'u': 0, 'z': 'pageview', 'v': 4}, {'t': 20, 'u': 0, 'z': 'pageview', 'v': 4}, {'t': 21, 'u': 0, 'z': 'pageview', 'v': 4}, {'t': 22, 'u': 0, 'z': 'pageview', 'v': 1}, {'t': 23, 'u': 0, 'z': 'pageview', 'v': 6}] - Reward: 0
観測 observationはOfflineの場合と同様なので割愛します.行動はどのプロダクトを推薦するかを選択します.
学習エージェントの記述
次にエージェントクラスを作成して,行動の選択,学習のメソッドの例を見ていきます.次の例ではPopularityAgentという学習(しない)エージェントを記述します.PopularityAgentはよく注文される商品を確率的によく推薦するようになるエージェントです.
import numpy as np
from numpy.random import choice
from agents import Agent
# Define an Agent class.
class PopularityAgent(Agent):
def __init__(self, config):
# Set number of products as an attribute of the Agent.
super(PopularityAgent, self).__init__(config)
# Track number of times each item viewed in Organic session.
self.organic_views = np.zeros(self.config.num_products)
def train(self, observation, action, reward, done):
"""Train method learns from a tuple of data.
this method can be called for offline or online learning"""
# Adding organic session to organic view counts.
if observation:
for session in observation.sessions():
self.organic_views[session['v']] += 1
def act(self, observation, reward, done):
"""Act method returns an action based on current observation and past
history"""
# Choosing action randomly in proportion with number of views.
prob = self.organic_views / sum(self.organic_views)
action = choice(self.config.num_products, p = prob)
return {
**super().act(observation, reward, done),
**{
'a': action,
'ps': prob[action]
}
}
このPopularity AgentはOfflineで学習して,Onlineで学習した結果を利用して推薦するというようなエージェントになります.最初に出てきたConfigをコンストラクタで受け取りスーパークラスに渡しています.actメソッドは推薦を決定するためのロジックを記述します. train は学習のためのコードを記述します.
学習と推薦
ここではOfflineでの学習とOnlineでの推薦の様子を見ていきます.
# Instantiate instance of PopularityAgent class.
num_products = 10
agent = PopularityAgent(Configuration({
**env_1_args,
'num_products': num_products,
}))
# Resets random seed back to 42, or whatever we set it to in env_0_args.
env.reset_random_seed()
# Train on 1000 users offline.
num_offline_users = 1000
for _ in range(num_offline_users):
# Reset env and set done to False.
env.reset()
done = False
observation, reward, done = None, 0, False
while not done:
old_observation = observation
action, observation, reward, done, info = env.step_offline(observation, reward, done)
agent.train(old_observation, action, reward, done)
# Train on 100 users online and track click through rate.
num_online_users = 100
num_clicks, num_events = 0, 0
for _ in range(num_online_users):
# Reset env and set done to False.
env.reset()
observation, _, done, _ = env.step(None)
reward = None
done = None
while not done:
action = agent.act(observation, reward, done)
observation, reward, done, info = env.step(action['a'])
# Used for calculating click through rate.
num_clicks += 1 if reward == 1 and reward is not None else 0
num_events += 1
ctr = num_clicks / num_events
print(f"Click Through Rate: {ctr:.4f}")
ここでは処理が大きく2段階に分かれています.これまで述べて来たOfflineとOnlineです.1つ目のfor文の中身がOfflineになり,2つ目のfor分の中身がOnlineになります.1つめのfor文はOfflineの説明で説明したような処理にagent.trainが含まれています.ここで,環境内に設定された固定方策でどんな行動を選択したかaction,その結果どんな観測になったかobservation,報酬は?reward,終了したかどうかdoneの情報を用いてpopularityAgentは学習します.2つめに関してはagent.actが含まれています.ここでは,学習結果を用いて,推薦を行っています.最終的にCTRを出力するというようなコードになっています.
テスト
最後にテストに関して記述します.テストではベースラインとなるランダムエージェントと記述したエージェントを比較します.まず,これまで説明したような流れで環境とエージェントを用意してあげます.
import gym, reco_gym
from reco_gym import env_1_args
from copy import deepcopy
env_1_args['random_seed'] = 42
env = gym.make('reco-gym-v1')
env.init_gym(env_1_args)
# Import the random agent.
from agents import RandomAgent, random_args
# Create the two agents.
num_products = env_1_args['num_products']
popularity_agent = PopularityAgent(Configuration(env_1_args))
agent_rand = RandomAgent(Configuration({
**env_1_args,
**random_args,
}))
次に,テスト用のメソッドを用いてエージェントの性能評価します.テスト用メソッドには環境とエージェントを渡します.
reco_gym.test_agent(deepcopy(env), deepcopy(agent_rand), 1000, 1000) # Results # (0.010861454584063708, 0.010142751416190508, 0.011612952904052953) reco_gym.test_agent(deepcopy(env), deepcopy(popularity_agent), 1000, 1000) # Results # (0.013708692749119874, 0.01289481407303356, 0.014555633704346316)
第3引数はOfflineの時のユーザー数,第4引数はオンラインの時のユーザー数になります.今はどちらも1000人で設定しています.返り値としてはCTRとなります.1つ目がCTRの中央値,2つ目が下側2.5%点,3つ目が上側2.5%点の値になっています.RandomAgentよりはPopularityAgentの方が良いCTRになっていることがわかります.
おわりに
ここまでお付き合いありがとうございました.とりあえずざっと書いてみました.概要だけでも掴んでいただければなと思ってます.私もまだわからないところだらけなので,勉強し続けたいと思います.追加でシェアできる情報はこれからもシェアしていきたいと思います.
最後になりましたが,Datumixでは強化学習を用いた推薦システムを実装していこうとしています.推薦システムや強化学習に興味がある方,一緒に開発してみたいという方はぜひこちらからコンタクトを取っていただければ幸いです.