
機械学習×配送計画のアルゴリズム紹介
CTOの奥戸です.去年の9月頃からTwitterを始めました.今後も物流関連のニュース,会社の事業,考えていることをつぶやいていく予定です.
今回はトラックの運転手の方や配送係の方の業務に関わる配送計画について,機械学習を使った最近の動向を共有したいと思います.記事作成にはアルバイトで参加してもらっている中田さんに協力していただきました.
配送計画×機械学習
物流でも配送における機械学習の応用について紹介したいと思います.人手不足の上に物流の需要の高まりから,自動化と効率化は必須と言われています.紹介する技術によって配車係と言われる人たちの業務が軽減されると考えています.
配送計画
簡単に説明すると配送計画というのは,配送先が複数あったときにどのような順番で配送すれば最適か(一般的なものであれば配送にかかる時間が最も短くなるか)を考えることです.配車係の方はこのようなことを仕事で行っていると理解しています.これは,巡回セールスマン問題(TSP; Travel Salesman Problem)とも呼ばれます.巡回セールスマン問題に様々な制約(トラックの台数やトラックが運べる荷物の量の制限や配送先に到着しなければならない時間など)が加わることで問題が複雑化していきます.様々な制約も考慮した巡回セールスマン問題を配送計画問題と呼びます.(単純な巡回セールスマン問題も配送計画問題と呼ばれることもあります.)
つまり,配車係の方は業務で配送経路問題を解いているとも言えます.
配送計画における組み合わせ最適化
配送計画問題はこれまでに様々な研究がされており,組み合わせ最適化の手法を使って解かれます.遺伝的アルゴリズムやLK-Hアルゴリズムなどいくつか存在します.ちなみにLK-Hアルゴリズムは弊社内でライブラリを開発したこともありました.古くからあるアルゴリズムのため,いくつかの企業が配送計画を軸にした製品を出しています.これらの多くは組み合わせ最適化において従来法を使っていると理解しています.
機械学習を用いるメリット
では,機械学習を用いることで従来法に比べてどういったメリットがあるのでしょうか?
大きく2つあると考えています.
精度の向上
最適な解を求めるために,必要な情報が全て揃っていれば(膨大な時間がかかりますが,)一番良い解を求めることができます.しかしながら,揃わない場合の方が多いです.そうした場合には,知りたい情報を知るために他の情報を使って推定する必要があります.その推定の精度が機械学習を用いることによって向上するため,求めることができる配送経路の精度がよくなります.
計算量の削減
先ほど,
必要な情報が全て揃っていれば(膨大な時間がかかりますが,)一番良い解を求めることができます.
という説明をしました.ただし,考慮する情報が多すぎると膨大な時間がかかります.どれほど膨大かというと,人が生きている間には計算が終わらないほどです.これは実質,解けていないのと同じです.機械学習は学習に膨大な時間がかかりますが,学習されたモデルを使う場合は少ない時間で結果を出力できます.
ここからは少し,専門的な話になりますが,具体的な論文を紹介します.
論文の紹介
Neural Combinatorial Optimization with Reinforcement Learning
Irwan Bello, Hieu Pham, Quoc V. Le, Mohammad Norouzi, Samy Bengio
https://arxiv.org/abs/1611.09940
配送計画問題を強化学習と呼ばれる機械学習の手法を使用して解いた論文を紹介します.強化学習についての説明はここでは避けます(今後ブログで書くかもしれません).かなりざっくりと説明すると状況判断を繰り返すような問題において,良い状況判断を学習することができる手法のことです.例を用いると,強化学習はゲームのプレイ学習でよく使用されます.例えばマリオにおいて,プレイ画面に表示された状況(画面)を見てプレイヤーはどのボタンを押すかという判断をします.そして,コインをゲットしたりゴールに到達するとポイントをゲットできたり,クリアできます.このポイントのゲットやクリアできるような状況判断を学習します.強化学習の用語ではこの状況を「状態」,判断を「行動」,ポイントゲットやクリアを「報酬」と呼ばれる形で表現します.

この論文では,以下のような強化学習の設定で配送経路問題が解かれています.マリオと合わせて表にしてみました.
| マリオ | 配送計画 | |
| 状態 | プレイ画面 | どの配送先にいるか |
| 行動 | ボタン操作 | どの配送先に移動するか |
| 報酬 | クリア,コインの獲得… | 配送先間の移動にかかる時間(ペナルティ) |
学習対象であるモデルには深層学習モデルの一種であるLSTMを用いています.LSTMは可変長のデータを扱うことができます.このLSTMを2つ組み合わせたようなネットワーク構造のモデルを使用しています.下記に図を示します.
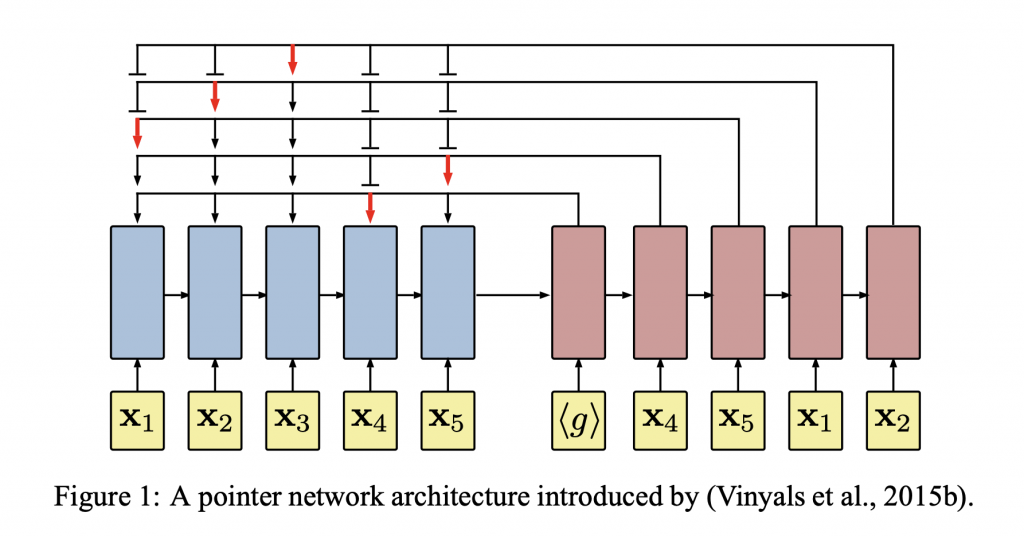
青いネットワークはエンコーダーを示しています.エンコーダーは状態(座標:現在どこの配送先にいるかという情報)を潜在変数に変換する役割を担います.赤いネットワークはデコーダーを示しており,状態を入力とし,次に訪れる配送先を探すために用いるキーとなる値を出力します(図中の赤い矢印).次の配送先は先ほど出力されたキーとなる値と配送先候補の潜在変数の内積から得られた値を用いて,求めます.(図中の<g>は学習可能なパラメータを表しています.)このモデルは上表で示した報酬を受け取りながら,強化学習により学習していきます.
実験
評価のための実験は巡回セールスマン問題のデータを用いて行われました.100個の配送先が存在し,最も時間がかからない配送順を導く問題です.下図にイメージを示します.
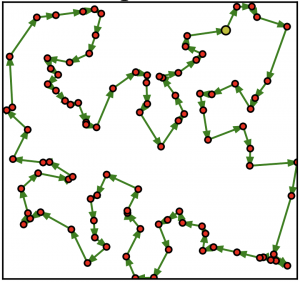
赤色の点が配送先で,黄色が拠点を示しています.この図は拠点と配送先が与えられたときの最適な配送順を緑の矢印で示しています.実際には拠点と配送先だけが与えられて,配送順を求める問題です.
論文中では性能と計算速度の評価が行われています.
性能は出力された配送計画によってどれだけのコスト(距離や時間)で配送先を回れたかを示す指標で比較します.

計算速度の評価でも出てくるものに絞って比較対象を説明します.Googleが提供するOR Toolのlocal searchと最適化手法のソルバー(ConcordeとLK-H)です.RL pretrainingが提案手法を示しています(greedyは一つのモデルが予測した配送順を選ぶ方法で,greedy@16は16個のモデルが予測した配送順のうち,最もコストが小さい配送順を選ぶ方法を示しています.).RL pretrainingの項目にある手法が他の手法に比べて,同等以上の性能であることがわかります.
次に計算速度の比較です.

表の数字は平均実行時間を表しており,提案された手法が最も早く配送順を算出できていることがわかります.こちらもRL pretrainingの計算速度が既存のものよりも早いことが分かります.OR-Tools’ local searchもなかなか早いですね.
ここまで性能と計算速度において他の手法との比較結果を見ました.RL pretrainingを使った手法はどちらも優れた結果であることが分かります.しかし,組み合わせるアルゴリズムによって性能と計算速度にばらつきがあることが分かります.計算速度を重視したい場合と性能を重視したい場合で組み合わせるアルゴリズムを変える必要があるかと思います.例えば計算速度を重視したいのであれば,greedyをもちいて,性能を重視したいのであれば,AS(Active Search;説明は省きます.詳しくは論文)を用いるとよいと思います.
拡張の可能性
この実験では,単純な巡回セールスマン問題で実験が行われました.しかしながら状態や報酬の設計次第でさまざまな条件への拡張が可能と考えられます.例えばトラックの積載容量などを状態に入れたり,混雑状況に応じて報酬を生成したりなどの工夫が考えられます.
最後に
今回は配送計画×機械学習というテーマを取り上げました.機械学習を用いると既存の手法よりも早く計算結果を出力することができるようになるという利点がありました.こちらは本文でも触れましたが,これまで解けなかったような問題が解けるようになるという可能性を秘めています(具体的にはこれまで考慮できていなかった情報を考慮して良い配送順を求めたりすること).これまで既存のものでは解決できなかった課題がクリアされ,自動化につながるかもしれません.
弊社は機械学習の技術を物流業界に展開することで,物流の課題解決を目指しています.物流関連の課題を機械学習を用いて解決したいなどの要望がございましたら,お気軽にお問い合わせください.